Cosa è Cuda?
“CUDA è un'architettura di elaborazione in parallelo realizzata da NVIDIA che permette netti aumenti delle prestazioni di computing grazie allo sfruttamento della potenza di calcolo delle GPU (unità di elaborazione grafica)” (fonte Nvidia). Per fare ciò Nvidia si è inventata il linguaggio “Cuda”.
“Cuda” è un linguaggio derivato dal C con il quale scrivere codice che verrà eseguito dalla GPU.
Ci sono dei miglioramenti?
Dipende, si deve tenere conto delle differenti architetture e scopi per le quali sono state create CPU e GPU, ma negli ultimi tempi c’è sempre più enfasi sul fatto che le GPU possano eseguire codice in modo più veloce rispetto alla cpu, questo è vero soprattutto in determinati contesti.
Vi ricordate il passaggio di nvidia dalla serie 7000 alla serie 8000(G80) la grande novità era l’architettura a shader unificati (multi purpose).
Prima della serie G80 le schede video avevano vertex e pixel shader separati, adesso con le nuove architetture abbiamo un unico tipo di shader in grado di eseguire le funzioni di entrambi.
Con il tempo il numero di questi shader è andato aumentando per esempio sulla 8800GTX ce ne earno 96, GTX280 ne aveva 256 adesso la GTX480 ne ha 512. (adesso Nvidia li chiama Cuda Core).
Queste unità elaborative possono essere assimilate (NON E’ LA STESSA COSA) a dei core fisici sui quali mandare in esecuzione thread in parallelo, più ne abbiamo e più possiamo parallelizzare.
Quindi per rispondere alla domanda ci sono miglioramenti? Si se il calcolo è parallelizzabile.
A proposito sto parlando di Nvidia e Cuda solo perché ho sempre avuto una scheda Nvidia ma la stessa tecnologia esiste su ATI ovviamente non Cuda che è proprietaria ma con OpenCL che è uno standard aperto che si prefigge gli stessi scopi vedi Directx e OpenGL.
Cuda per adesso è solo implementabile e supportato da Nvidia via c++, ma una società ha creato delle librerie per poter interfacciarsi a cuda via .net (GASS.CUDA) scaricabili gratuitamente al sito http://www.hoopoe-cloud.com/Solutions/CUDA.NET/Default.aspx#releases sono presenti degli esempi in c#.
Il nostro tutorial.
Premessa “NON SONO UN ESPERTO DI CUDA”.
Questo tutorial non vuole essere una spiegazione del linguaggio Cuda o OpenCL per i quali ci sono guide e tuorial un po’ da tutte le parti (e poi non ne sarei nemmeno in grado) ma solo un esempio di come poterlo utilizzare e i benefici che può portare.
L’applicazione che ho creato, e di cui tratto è il porting di una demo (Nbody) presente null’sdk 3.0 di Cuda (scaricabile all’indirizzo http://developer.nvidia.com/object/gpucomputing.htm), questa scritta in C++, Cuda, OpenGL, io utilizzando GASS.CUDA e lasciando quasi inalterata la parte cuda l’ho riscritta in c#, directx managed 9.0, per dimostrare che già oggi è possibile utilizzare .net per sfruttare cuda e per dare un idea dei miglioramenti che possiamo ottenere.
Problema: Simulare l’interazione gravitazionale tra N corpi.
Come possiamo intuire facilmente questa è una tipica simulazione dove la parte di calcolo è la parte piu gravosa, in quanto deve essere calcolata, per ogni corpo, l’interazione con tutti gli altri e all’aumentare di N (numero dei corpi) i calcoli da effettuare aumentano del quadrato.
Per esempio se abbiamo 100 corpi l’interazioni sono 10000 e così via.
Adesso un po' di fisica.
Dati N corpi con una posizione iniziale = xie con una velocità = vie per i 1<=i <= N il vettore forza fi,japplicato al corpo i causato dalla sua attrazione gravitazionale verso il corpo j è data da:

(*) i vettori sono in grassetto
Dove mi e mj sono le masse dei corpi i e j rispettivamente; ri,j= xi - xjè il vettore dal corpo i al corpo j, G è la costante gravitazionale. Il membro sinistro “la magnitudine della forza” è proporzionale al prodotto delle masse e inversamente proporzionale al quadrato delle distanza tra il corpo i e il corpo j. Il mebro di destra è la direzione della forza che è un vettore unitario che dal corpo i va verso il corpo j (la gravità è una forza attrattiva).
La forza totale Fi sul corpo i, dovuta alla sua interazione con gli altri N-1 corpi è ottenuta sommando tutte le sue interazioni:
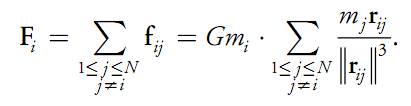
A livello esclusivamente numerico si nota come al tendere a 0 della distanza la forza tende a crescere indefinitamente, questo in un algoritmo è un problema. Nelle simulazioni astrofisiche le collisioni tra i corpi in genere sono eliminate, questo è ragionevole se i corpi rappresentano galassie che possono attraversarsi senza creare collisioni. Per questo possiamo aggiungere un termine e²>0 al denominatore e riscrivere come segue

Notiamo come la condizione j ≠ i non sia più necessaria perché fi,i = 0 per e²>0.
Per integrare attraverso il tempo (come tutti i sistemi particellari) abbiamo bisogno dell'accelerazione ai = Fi /mi per poter aggiornare posizione e velocità del corpo i, quindi semplificando abbiamo: (Demo Nbody Nvidia)

Implementazione:
Possiamo pensare ogni fi,j come ad una cella di una matrice NxN, e alla forza totale Fi (o l'accellerazione ai) come alla somma di tutte le celle della riga i-esima, questo calcolo può essere elaborato indipendentemente dalle altre righe, quindi di fatto il grado di parallelismo è O(N^2), questo tipo di parallelismo richiede tuttavia una pari quantitativo di memoria, e questo è limitato sostanzialmente dalla banda passante. Viene per questo motivo introdotto il concetto di "computational tile", in parole povere una sotto matrice quadrata di quella globale NxN formata da p righe e p colonne.
Nella sottomatrice PxP il parallelismo è implementato tra le righe mentre la serializzazione tra le colonne.

(Fonti:Documentazione Demo Nbody Nvidia)
Quindi a livello globale i punti di sincronizzazione sono alla fine di tutti gli N/P blocchi.
Per chi fosse interessato a tutta la spiegazione non resta che scaricarsi l'sdk Cuda toolkit 3 e vedere la documentazione completa. Per noi è sufficiente capire come tutto si basi sul parallelismo dell'elaborazione. In parole povere succede che mediamente queste N^2 interazioni vengono mandato in parallelo su una GTX280 su 1920 thread, mentre al massimo su una cpu 8 core può essere mandato su 8 thread in parallelo o poco più.
Ho tentato di creare un grid di thread anche sulla CPU ma ho avuto grossi problemi di sincronizzazione quindi a differenza di quanto fa Cuda sulla gpu, sulla cpu sono riuscito a mandare in parallelo un vettore di thread e non una matrice.
Parti del Codice salienti:
Per prima cosa vedrete nel progetto, e se scaricherete GASS.CUDA (ve lo consiglio vivamente) nei loro esempi, che ci sono dei file con estensione .cu (Cuda) questi sono i file sorgenti che vengono compilati dal compilatore Cuda "nvcc.exe" presente nell'sdk.
Ricordate che i file cu in fin dei conti sono file C, quindi dovete avere anche il c++ (va bene anche il c++ express) installato se li volete compilare nel caso li modifichiate. La compilazione del file .cu crea un file .cubin che è la sua controparte binaria che effettivamente tramite comandi specifici (GASS.CUDA) verrà eseguito sulla GPU.
Per compilare il file .CU dovrete mettere negli eventi post compilazione il seguente comando:
nvcc nbody_kernel.cu -cubin --compiler-bindir=”C:\Program Files\Microsoft Visual Studio 9.0\VC\bin
"nbody_kernel.cu" è il file .cu che verrà compilato e avrà come risultato, se tutto va bene, un file che si chiamerà "nbody_kernel.cubin".
per i sistemi x64 (avendo installato il cuda toolkit a 64 bit) il problema fondamentale è che cuda viene compilato a 64bit ma le directx managed (quelle dell'sdk di microsoft) come sappiamo funzionano solo a 32. Così facendo otteniamo che, o va cuda, o vanno le directX. Il file .cubin che c'è nella demo è compilato a 32bit, quindi compilando la soluzione a 32bit tutto funziona.
Per chi volesse usare le directx managed a 64 bit di terze parti e volesse ricompilare il file .cu a 64bit basta aggiungere la riga qui sotto nell'evento post compilazione:
nvcc nbody_kernel.cu --cubin --compiler-bindir="C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\bin" -I="C:\Program Files (x86)\Microsoft Visual Studio 9.0\VC\include".
Passiamo al codice; la parte più interessante è senza dubbio la parte che si occupa di Cuda. Nella mia implementazione è la classe: ParticleSystemCuda
Inizializzazione:
cuda = new CUDA(0, true);
crea il device Cuda (0,true) => 0 il primo device nel caso abbiate più schde video sara 1 o 2... , true se lo vogliamo inizializzare.
cuda.LoadModule("nbody_kernel.cubin");=>Carica il modulo binario che abbiamo compilato.
CUfunction fun = cuda.GetModuleFunction("integrateBodies"); => crea un riferimento alla funzione principale che vogliamo sia eseguita.
Passaggio dei parametri alla funzione:
Come di norma quasi tutte le funzioni e o sub vengono passati valori e in genere ne ritornano altri modificati. questo può avvenire in due modi normalmente o è una funzione in senso stretto che ritorna dei valori o è una sub a cui passiamo per riferimento delle variabil che verranno modificare all'interno del codice. "in c puntatori".
La funzione integrateBodies ha la seguente firma:
extern "C" __global__ void integrateBodies(float4* newPos, float4* newVel,float4* oldPos, float4* oldVel,float deltaTime, float damping, float asquared, int numBodies)
Notare la sintassi cuda "__global__" significa che questa funzione verrà compilata e indirizzata dal compilatore cuda. "extern" è la parola chiave che dovrete mettere per far si che la funzione sia riconosciuta da GASS.CUDA come funzione richiamabile. Notate come i primi 4 parametri siano puntatori a float4 di cui nei primi due verranno memorizzate le nuove velocità e posizione dei corpi partendo da quelli vecchi. Il parametro "asquared" è stato aggiunto da me, perchè nella versione originale veniva utilizzata una costante __constant__ float softeningSquared; che non sono riuscito a indirizzare tramite GASS.CUDA per problemi di contesto.
Per passare i parametri alla funzione cuda dobbiamo distinguere tra quelli che utilizzeremo per farci tornare i valori modificati e quelli che devono semplicemente essere passati, e dal tipo di riferimento.
Per i primi e riferimento (puntatore):
CUdeviceptr posoutput = cuda.Allocate((uint)(Marshal.SizeOf(afloat4) * m_numparticles));
CUdeviceptr veloutput = cuda.Allocate((uint)(Marshal.SizeOf(afloat4) * m_numparticles));
posoutput e veloutput sono i puntatori all'area di memoria dove verranno ritornati i valori, le istruzioni sotto settano i parametri; notare che non è stato passato nulla a cuda solo allocato un area di memoria sarà cuda a tornare i valori.
cuda.SetParameter(fun, 0, (uint)posoutput.Pointer);
cuda.SetParameter(fun, IntPtr.Size, (uint)veloutput.Pointer);
per il secondo tipo (sempre per riferimento):
CUdeviceptr posinput = cuda.CopyHostToDevice(cudapos);
CUdeviceptr velinput = cuda.CopyHostToDevice(cudavel);
posinput e velinput sono i puntatori all'area di memoria dove verranno passati i valori con la prossima istruzione: notare la differenza con i primi dove adesso dobbiamo passare noi dei valori a cuda e lo facciamo con le variabili cudapos e cudavel che sono effettivamente vettori GASS.float4 valorizzati, in quanto contengono le posizoni e le velocità correnti che cuda aggiornerà e ripasserà nell'area di memoria posoutput e veloutput. Le istruzioni sotto servono per settare i parametri alla funzione.
cuda.SetParameter(fun, IntPtr.Size * 2, (uint)posinput.Pointer);
cuda.SetParameter(fun, IntPtr.Size * 3, (uint)velinput.Pointer);
le 4 istruzioni sotto settano i parametri passati per valore, vediamo come la cosa sia più semplice, qui non abbiamo bisogno di puntatori.
cuda.SetParameter(fun, IntPtr.Size * 4, m_deltatime);
cuda.SetParameter(fun, IntPtr.Size * 4 + 4, m_damping);
cuda.SetParameter(fun, IntPtr.Size * 4 + 8, m_softeningSquared);
cuda.SetParameter(fun, IntPtr.Size * 4 + 12, (uint)m_numparticles);
prendiamo in esame adesso la sequenza completa delle setparameter:
cuda.SetParameter(fun, 0, (uint)posoutput.Pointer);
cuda.SetParameter(fun, IntPtr.Size, (uint)veloutput.Pointer);
cuda.SetParameter(fun, IntPtr.Size * 2, (uint)posinput.Pointer);
cuda.SetParameter(fun, IntPtr.Size * 3, (uint)velinput.Pointer);
cuda.SetParameter(fun, IntPtr.Size * 4, m_deltatime);
cuda.SetParameter(fun, IntPtr.Size * 4 + 4, m_damping);
cuda.SetParameter(fun, IntPtr.Size * 4 + 8, m_softeningSquared);
cuda.SetParameter(fun, IntPtr.Size * 4 + 12, (uint)m_numparticles);
Primo parametro della funzione "SetParameter" :
"fun" -> il puntatore alla funzione per la quale vogliamo settare i parametri.
Uint -> il punto di inizio dell'area di memoria relativa al parametro che stiamo passando.
3 parametro:o il valore del puntatore o il valore della variabile.
la riga: cuda.SetParameterSize(fun, (uint)(IntPtr.Size * 4 + 16));
descrive a CUDA l'area totale della memoria nella quale vengono passati i parametri.
Lancio della funzione e settaggio dei thread:
cuda.SetFunctionBlockShape(fun, (int)(BLOCKSIZE),_q, 1);
cuda.SetFunctionSharedSize(fun, (uint)(sharedmemsize));
queste due istruzioni mi hanno fatto impazzire per farle andare. La prima decide la dimensione dei blocchi di thread, la seconda setta il quantitativo di memoria shared di cui i thread si servono per condividere i dati. Queste due funzioni sono interconnesse nel senso che dipendono una dall'altra. io personalmente non sono riuscito a trovare un algoritmo che le lega ma provando e riprovando ho trovato valori con cui tutto funziona. la lista dei valori è nei sorgenti. (con valori diversi otteniamo come risultato che cuda restiruisce vettori null se ci volete provare :) )
per esempio:
BLOCKSIZE = 16 fisso
_q=2 fisso
_p = 512
Ne consegue che
sharedmemsize = (int)(BLOCKSIZE * _q * Marshal.SizeOf(afloat4));
NUMEROPARTICELLE = _p * BLOCKSIZE = 8192
se _p = 1536 => _p * BLOCKSIZE = NUMEROPARTICELLE = 24576
la riga sotto indica a Cuda di lanciare l'esecuzione della funzione su una griglia di _px1 thread.
cuda.Launch(fun, _p, 1);
Mentre questa aspetta la fine dell'esucuzione.
cuda.SynchronizeContext();
con le prossime due istruzioni ci recuperiamo i valori modificati da cuda tramite i puntatori posoutput e veloutput e li salviamo nei nostri vettori cudaposnew e cudavelnew.
cuda.CopyDeviceToHost(posoutput, cudaposnew);
cuda.CopyDeviceToHost(veloutput, cudavelnew);
le prossime 4 istruzioni liberano la memoria di cuda
cuda.Free(posoutput);
cuda.Free(veloutput);
cuda.Free(posinput);
cuda.Free(velinput);
In cuda tutto ciò che è "device" riguarda la GPU tutto ciò che è "Host" rigurda il chiamante.
Per la parte cpu non sto a dilungarmi, si commenta da sola, l'unica considerazione è che dato il numero limitato di core il numero di thread deve essere necessariamente molto inferiore conseguentemente il numero di corpi per deve diminuire drasticamente per un frame rate decente.
Perormance e Considerazioni:
Sul mio hardware:
intel core i7 920 @ 3800 8 core (HT)
4000 corpi per 8 thread a 21fps CPU 98%
Gtx 280
_p= 1536 thread
24576 corpi a 21 FPS GPU 98%
come vedete c'è una differenza di qusi 5 volte ma ricordando che la complessità del calcolo aumenta con il quadrato del numero dei corpi possiamo dire che per questo tipo di applicazione la gtx280 è circa 25 volte più potente di un intel core i7 920@3800.
Mi sembra di avere detto tutto, spero sia stato di vostro interesse.
Per i sorgenti, discussione, immagini venite sul forum di notjustcode:
http://www.notjustcode.it/forum/viewtopic.php?f=21&t=454
per qualsiasi miglioramento, consiglio o parere non esitate.
Sta a voi adesso a provare sui vostri HW.
Per chi volesse cimentarsi:
- Per eseguire la demo:
- Directx DSK (Febbraio 2010)
- Parte GPU: una gpu nvidia compatibile con CUDA (http://www.nvidia.it/object/cuda_gpus_it.html)
- Per compilare/modificare
- Directx DSK (Febbraio 2010)
- c# express 2008
- compilare cuda: c++ (express 2008), sdk cuda 3.0
- Gass.Cuda
Un ringraziamento particolare a RobyDx per avermi ospitato e per avermi aiutato con i suoi tutorial nella parte grafica.
Un Saluto
lupo.alberto0069@gmail.com
Prima Versione
Sorgente
Seconda Versione