Con la crescente potenza e versatilità delle schede video sono nate negli ultimi anni diverse tecnologie volte ad utilizzare la GPU per operazioni diverse dal rendering di grafica. Tra le tecnologie volte a questo scopo c’è ad esempio CUDA di nVidia, OpenCL e, nel caso di DirectX11, le Direct Compute.
Sotto il nome di Direct Compute c’è un sotto insieme di funzioni Direct3D per l’esecuzioni di calcoli matematici tramite l’utilizzo dei Compute Shaders, degli speciali Shader che anziché entrare nella pipeline grafica non fanno altro che leggere e scrivere su appositi buffer di memoria.
Al termine dell’operazione sarà sufficiente andare a leggere i dati da tale buffer e farci ciò che serve. Il vantaggio dei Compute Shader non è tanto nella potenza di calcolo per singola operazione ma per il fatto che sono ottimizzate per lavorare su vettori e soprattutto lavorano con un elevatissimo numero di processi in parallelo raggiungendo, se utilizzate correttamente, prestazioni irraggiungibili per qualsiasi CPU. Gli utilizzi spaziano dai giochi (esempio per l’intelligenza artificiale) alle applicazioni che con la grafica non c’entrano nulla come ad esempio funzioni statistiche.
Questo articolo introdurrà l’argomento che è di fatto vasto ed apre una quantità di scenari grandissima.
Un Compute Shader presenta molte caratteristiche che lo differenziano dagli altri Shader. Innanzitutto la funzione non restituisce nulla ma lavora attraverso l’uso di speciali buffer chiamati Unordered Access View. Questi buffer, passati al DeviceContext in modo simile ai normali Constant Buffer, permettono di leggere e scrivere all’interno di essi. Dal codice C++ verrà creato un buffer di tipo UAV (abbreviazione del nome completo) e all’interno dello shader sarà presente come variabile di una delle tipologie a disposizione.
- AppendStructuredBuffer
- Buffer
- ByteAddressBuffer
- ConsumeStructuredBuffer
- RWByteAddressBuffer
- RWStructuredBuffer
- RWTexture1D
- RWTexture1DArray
- RWTexture2D
- RWTexture2DArray
- RWTexture3D
Non tutte supportano sia lettura che scrittura (AppendStructuredBuffer ad esempio permette solo di aggiungere valori come fosse una lista). Alcune inoltre permettono anche il supporto a Template (Generics per i programmatori .Net e Java).
Esempio
RWStructuredBuffer buffer;
Dove MyStruct è una struttura a mio piacere.
Tutte queste avranno un unico corrispettivo nel codice, l’oggetto ID3D11UnorderedAccessView che di fatto è una vista su un ID3D11Buffer. Entrambi andranno gestiti in quanto il primo è una vista al secondo che sarà utilizzato per estrarre o inserire dati. Ecco come vengono creati
ID3D11Buffer* viewBuffer;
D3D11_BUFFER_DESC sbDesc ;
sbDesc.BindFlags = D3D11_BIND_UNORDERED_ACCESS | D3D11_BIND_SHADER_RESOURCE;
sbDesc.Usage = D3D11_USAGE_DEFAULT;
sbDesc.CPUAccessFlags = 0;
sbDesc.MiscFlags = D3D11_RESOURCE_MISC_BUFFER_STRUCTURED;
sbDesc.StructureByteStride = sizeOfStruct;
sbDesc.ByteWidth = sizeOfStruct * size;
hr = device->CreateBuffer(&sbDesc,NULL,&viewBuffer);
ID3D11UnorderedAccessView* view;
D3D11_UNORDERED_ACCESS_VIEW_DESC sbUAVDesc;
sbUAVDesc.Buffer.FirstElement=0;
sbUAVDesc.Buffer.Flags=0;
sbUAVDesc.Buffer.NumElements=TotalSize;
sbUAVDesc.Format = DXGI_FORMAT_UNKNOWN;
sbUAVDesc.ViewDimension = D3D11_UAV_DIMENSION_BUFFER;
hr=device->CreateUnorderedAccessView(viewBuffer,&sbUAVDesc,&view);
Non molto diversi dal consueto.
Attenzione:
- Le opzioni MiscFlags del Buffer e Flags e Format dell’ UnorderedAccessView vanno impostate in base al tipo di buffer nel codice HLSL. Nell’esempio ho usato un RWStructuredBuffer ma ognuno varia. Consultate l’help per vedere ognuno cosa vuole.
- La dimensione deve essere multipla di 32bit
Ora è necessario creare l’oggetto ID3D11ComputeShader, cosa che avviene in modo identico agli altri Shader. Quindi passiamo i dati al DeviceContext
context->CSSetShader(computeShader,NULL,0);
E passiamo i buffer UAV
context->CSSetUnorderedAccessViews(start,count,&views,NULL);
Il primo element è l’indice dell’array views di ID3D11UnorderedAccessView e count il numero di elementi da caricare. L’ultimo valore passato a NULL nell’esempio va utilizzato nel caso di buffer di tipo Append o Consume (nel primo caso una lista a cui aggiungere valori, nel secondo valori da cui estrarre dati). In questo caso è possibile passare un array di interi (uno per ogni buffer) che ci darà il numero iniziale di valori (ad esempio una lista append precedentemente riempita di 100 elementi può essere usata una seconda volta sovrascrivendo solo gli ultimi 50 valori e non tutti gli altri).
Ora si manda in esecuzione il codice tramite l’istruzione Dispatch che eseguirà la funzione il numero di volte che decideremo.
Context->Dispatch(X,Y,Z);
Prima però andiamo a spiegare come funziona il parallelismo. Il codice di un Compute Shader è una funzione HLSL eseguita tantissime volte in parallelo. Il numero di esecuzioni è indicato in gruppi tramite 3 valori interi XYZ come a rappresentare una scacchiera a 3 dimensioni. Ogni gruppo a sua volta ha 3 valori che indicano il numero Thread per ogni gruppo da eseguire. Il gruppo di Thread è un concetto importante in quanto un gruppo è in grado di condividere non solo un buffer UAV, ma anche variabili comuni.
Se ad esempio definisco una variabile in questo modo
groupshared float4 myVal;
Questa sarà condivisa in lettura e scrittura tra tutti i thread del gruppo come variabile di appoggio.
Ovviamente sarà impossibile prevedere l’ordine ed i tempi di esecuzione di ogni thread quindi sarà necessario gestire l’accesso contemporaneo agli oggetti. Ci sono tuttavia delle istruzioni in grado di sincronizzare i thread creando un’attesa finchè tutte le funzioni di un gruppo non siano arrivate allo stesso punto. Ad esempio GroupMemoryBarrier fa in modo che nessuna funzione di un gruppo non superi questa istruzione finchè gli altri thread dello stesso gruppo non hanno completato l’accesso alle variabili condivise mentre GroupMemoryBarrierWithGroupSync fa anche in modo che le istruzioni raggiungano esattamente questa funzione prima che tutte proseguino. Allo stesso modo ci sono funzioni che gestiscono l’accesso ai buffer UAV.
Il vantaggio delle variabili groupshared è la maggiore velocità e comodità di gestione. Thread di gruppi diversi comunicheranno invece solo tramite i buffer UAV e non potranno essere sincronizzati tra loro.
L’istruzione Dispatch indicherà il numero di gruppi da eseguire. Una scheda video DirectX11 gestisce a pieno le funzionalità ComputeShader ed è in grado di eseguire fino a 65536 gruppi per asse ossia quasi 300000 miliardi di gruppi mentre per ogni gruppo si può raggiungere un limite di 1024 thread per l’asse XY e 64 per l’asse Z. Ovviamente è un limite puramente teorico in quanto qualsiasi scheda video andrebbe in crash ma l’esecuzione di milioni di thread è un compito estremamente semplice per una scheda di fascia medio alta e tale valore non farà altro che migliorare nel tempo.
Vediamo ora come è strutturato un Compute Shader
Struct MyStruct
{
Float4 colore;
};
RWStructuredBuffer inOutBuff;
[numthreads( thread_group_size_x, thread_group_size_y, 1 )]
void CSMain( uint3 int idx = dispatchThreadID.y * threadIDInGroup : SV_GroupThreadID, uint3 groupID : SV_GroupID, uint groupIndex : SV_GroupIndex, uint3 dispatchThreadID : SV_DispatchThreadID )
{
//valori per riga
int stride = thread_group_size_x * N_THREAD_GROUPS_X;
//indice linearizzato
stride + dispatchThreadID.x;
inOutBuff [ idx ].colore= float4(1,1,1,1);
}
E’ possibile vedere una funzione CSMain che per semplicità non fa altro che valorizzare un RWStructeredBuffer con un float4 contenente tutti 1. L’attributo numthreads indica quanti thread per asse XYZ la scheda eseguirà.
Vediamo anche che il metodo non restituisce nulla e che ha in ingresso diversi valori.
- SV_GroupThreadID: indica il thread del gruppo eseguito. Sono 3 valori che vanno da 0 ai valori passati a numthreads per ogni asse
- SV_GroupID: restituisce l’ID del gruppo. Sono 3 valori che variano da 0 al valore passato al metodo Dispatch del DeviceContext
- SV_GroupIndex: indica l’id del gruppo ma come valore unico da 0 ai valori X*Y*Z di numthreads
- SV_DispatchThreadID: unisce GroupThreadID e GroupID. I valori andranno da 0 al prodotto tra quello di numthreads e Dispatch per ogni asse. Se quindi abbiamo 32 thread per asse e passiamo al metodo Dispatch il valore 4 allora si andrà da 0 a 127 incluso
Questi valori ci permettono di sapere in quale punto ci troviamo. Ecco come ad esempio possiamo ottenere un valore consecutivo unico per ogni thread
int stride = numthreadsX * numDispatchX;
int idx = dispatchThreadID.y * stride + dispatchThreadID.x;
Il valore stride è il numero di thread totali lungo la X mentre idx è il valore unico che ci identificherà il thread. Le costanti numthreadsX e numDispatchX saranno definite da noi in modo che coincidano con quelle definite nello shader e nel metodo Dispatch.
Al termine del metodo Dispatch possiamo leggere il risultato facendo una copia del buffer associato all’UAV su uno di tipo Staging e facendo l’operazione di Map.
Attenzione: il metodo Dispatch è asincrono. Significa che il codice continuerà a funzionare anche se lo shader non ha terminato il suo compito a meno di funzioni che accedano al buffer come appunto Map. Un’altra istruzione che forza la conclusione del codice compute shader è il metodo Flush del DeviceContext, usato anche per la demo. Normalmente sarà invece preferibile andare avanti con il rendering mentre la scheda termina il calcolo.
Oltre alla possibilità di usare buffer UAV il Compute Shader può usare i normali ConstantBuffer e le Texture. Al contrario i buffer UAV possono essere usati anche nei Pixel Shader.
L’argomento è tutt’altro che esaurito ma vi lascio ad un primo esempio che esegue 64 x 64 gruppi di threads da 32x32, un totale di quasi 5 milioni di esecuzioni. Il calcolo eseguito è la formula di Mac Laurin dell’esponenziale. Ai fini del tutorial non è necessario sapere come funziona ma vi rimando per cultura personale a quello che è uno dei tanti sgraditi argomenti matematici delle facoltà universitarie.
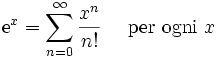
Il rapporto è stato di 6-7 secondi quando eseguito dalla CPU a meno di 20 ms quando eseguito dalla scheda video. Il confronto è quindi impietoso e la CPU ne esce sconfitta.
Come ultimi appunti ricordo che è possibile usare i compute shader anche su schede che non supportano le DirectX11 con alcune limitazioni quali l’obbligo di usare solo 1 come valore per i Threads sull’asse Z e massimo 768 come valori su XY. Anche la dimensione della memoria condivisa scende da 32kb a 16kb.
Vi lascio l’esempio, in futuro ci sarà modo di approfondire il Compute Shader con esempi di come sfruttarne la potenza.
Demo CPP
Demo .Net
I commenti sono disabilitati.

 Articolo
Articolo  Storico
Storico Stampa
Stampa

 Feed RSS 0.91
Feed RSS 0.91 Feed Atom 0.3
Feed Atom 0.3